| 2020人工智能领域研究热点(一):深度学习 |
| 发表时间:2020-12-14 阅读次数:7370 |
本文通过对2018—2020年的发文进行分析,结合使用次数、被引次数等指标,筛选了2020人工智能领域的Top20研究热点。本期对深度学习这一研究热点的数据特征进行展示。 近年来,深度学习领域不仅在理论上有所突破,在不同领域也有较好的应用前景。深度学习领域的主要研究机构(按被引用排序)有谷歌公司、中国科学院、伦敦大学、牛津大学、伦敦大学学院、Facebook公司、约翰霍普金斯大学、中国科学院大学、中国科学院自动化研究所和加州大学系统等。
深度学习领域的主要研究者(按被引用排序)有Chen, Liang-Chieh(Google Incorporated)、Shen, Li(University of Oxford)、Hu, Jie、Sun, Gang、Papandreou, George(Google Incorporated)、Yuille, Alan L.(Johns Hopkins University)、Murphy, Kevin(Google Incorporated)、Kokkinos, Iasonas(University College London)、He, Kaiming(Facebook Inc)和Girshick, Ross(Facebook Inc)。
深度学习领域最受关注的主题词为Convolutional neural network、Object detection、Neural networks、Image classification、Transfer learning、Feature extraction、Semantic segmentation、Generated adversarial network、Domain adaptation、Deep neural networks、Computer vision、Task analysis、Image segmentation、Training、Machine learning等。
2020年深度学习领域最受关注的论文主要有:
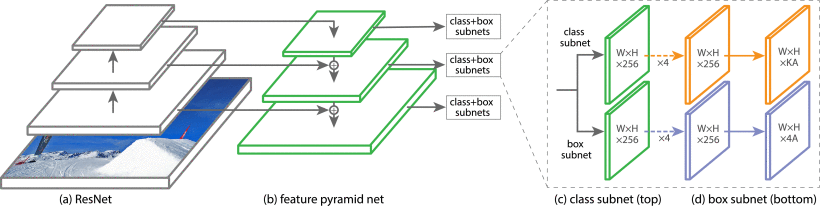
1.标题:Focal Loss for Dense Object Detection 作者: Lin, Tsung-Yi; Goyal, Priya; Girshick, Ross; 等. 期刊:IEEE TRANSACTIONS ON PATTERN ANALYSIS AND MACHINE INTELLIGENCE 会议: 16th IEEE International Conference on Computer Vision (ICCV) 会议地点: Venice, ITALY 会议日期: OCT 22-29, 2017 被引频次: 1,341 摘要:The highest accuracy object detectors to date are based on a two-stage approach popularized by R-CNN, where a classifier is applied to a sparse set of candidate object locations. In contrast, one-stage detectors that are applied over a regular, dense sampling of possible object locations have the potential to be faster and simpler, but have trailed the accuracy of two-stage detectors thus far. In this paper, we investigate why this is the case. We discover that the extreme foreground-background class imbalance encountered during training of dense detectors is the central cause. We propose to address this class imbalance by reshaping the standard cross entropy loss such that it down-weights the loss assigned to well-classified examples. Our novel Focal Loss focuses training on a sparse set of hard examples and prevents the vast number of easy negatives from overwhelming the detector during training. To evaluate the effectiveness of our loss, we design and train a simple dense detector we call RetinaNet. Our results show that when trained with the focal loss, RetinaNet is able to match the speed of previous one-stage detectors while surpassing the accuracy of all existing state-of-the-art two-stage detectors.
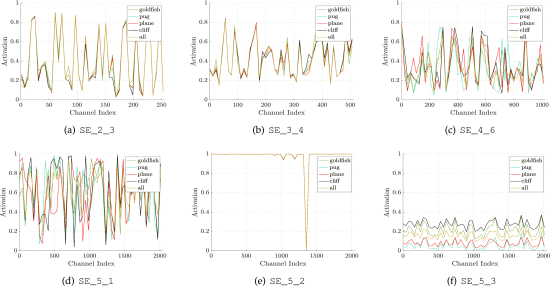
2.标题:Squeeze-and-Excitation Networks 作者: Hu, Jie; Shen, Li; Albanie, Samuel; 等. 期刊:IEEE TRANSACTIONS ON PATTERN ANALYSIS AND MACHINE INTELLIGENCE 会议: 31st IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) 会议地点: Salt Lake City, UT 会议日期: JUN 18-23, 2018 被引频次: 1,186 摘要:The central building block of convolutional neural networks (CNNs) is the convolution operator, which enables networks to construct informative features by fusing both spatial and channel-wise information within local receptive fields at each layer. A broad range of prior research has investigated the spatial component of this relationship, seeking to strengthen the representational power of a CNN by enhancing the quality of spatial encodings throughout its feature hierarchy. In this work, we focus instead on the channel relationship and propose a novel architectural unit, which we term the "Squeeze-and-Excitation" (SE) block, that adaptively recalibrates channel-wise feature responses by explicitly modelling interdependencies between channels. We show that these blocks can be stacked together to form SENet architectures that generalise extremely effectively across different datasets. We further demonstrate that SE blocks bring significant improvements in performance for existing state-of-the-art CNNs at slight additional computational cost. Squeeze-and-Excitation Networks formed the foundation of our ILSVRC 2017 classification submission which won first place and reduced the top-5 error to 2.251 percent, surpassing the winning entry of 2016 by a relative improvement of similar to 25 percent. Models and code are available at github.
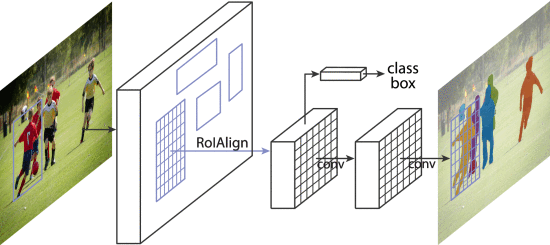
3.标题:Mask R-CNN 作者: He, Kaiming; Gkioxari, Georgia; Dollar, Piotr; 等. 期刊:IEEE TRANSACTIONS ON PATTERN ANALYSIS AND MACHINE INTELLIGENCE 会议: 16th IEEE International Conference on Computer Vision (ICCV) 会议地点: Venice, ITALY 会议日期: OCT 22-29, 2017 被引频次: 431 摘要:We present a conceptually simple, flexible, and general framework for object instance segmentation. Our approach efficiently detects objects in an image while simultaneously generating a high-quality segmentation mask for each instance. The method, called Mask R-CNN, extends Faster R-CNN by adding a branch for predicting an object mask in parallel with the existing branch for bounding box recognition. Mask R-CNN is simple to train and adds only a small overhead to Faster R-CNN, running at 5 fps. Moreover, Mask R-CNN is easy to generalize to other tasks, e.g., allowing us to estimate human poses in the same framework. We show top results in all three tracks of the COCO suite of challenges, including instance segmentation, bounding-box object detection, and person keypoint detection. Without bells and whistles, Mask R-CNN outperforms all existing, single-model entries on every task, including the COCO 2016 challenge winners. We hope our simple and effective approach will serve as a solid baseline and help ease future research in instance-level recognition.
4.标题:Deep Learning for Generic Object Detection: A Survey 作者: Liu, Li; Ouyang, Wanli; Wang, Xiaogang; 等. 期刊:INTERNATIONAL JOURNAL OF COMPUTER VISION 被引频次: 76 摘要:Object detection, one of the most fundamental and challenging problems in computer vision, seeks to locate object instances from a large number of predefined categories in natural images. Deep learning techniques have emerged as a powerful strategy for learning feature representations directly from data and have led to remarkable breakthroughs in the field of generic object detection. Given this period of rapid evolution, the goal of this paper is to provide a comprehensive survey of the recent achievements in this field brought about by deep learning techniques. More than 300 research contributions are included in this survey, covering many aspects of generic object detection: detection frameworks, object feature representation, object proposal generation, context modeling, training strategies, and evaluation metrics. We finish the survey by identifying promising directions for future research.
5.标题:Grad-CAM: Visual Explanations from Deep Networks via Gradient-Based Localization 作者: Selvaraju, Ramprasaath R.; Cogswell, Michael; Das, Abhishek; 等. 期刊:INTERNATIONAL JOURNAL OF COMPUTER VISION 会议: 16th IEEE International Conference on Computer Vision (ICCV) 会议地点: Venice, ITALY 会议日期: OCT 22-29, 2017 被引频次: 62 摘要:We propose a technique for producing 'visual explanations' for decisions from a large class of Convolutional Neural Network (CNN)-based models, making them more transparent and explainable. Our approach-Gradient-weighted Class Activation Mapping (Grad-CAM), uses the gradients of any target concept (say 'dog' in a classification network or a sequence of words in captioning network) flowing into the final convolutional layer to produce a coarse localization map highlighting the important regions in the image for predicting the concept. Unlike previous approaches, Grad-CAM is applicable to a wide variety of CNN model-families: (1) CNNs with fully-connected layers (e.g.VGG), (2) CNNs used for structured outputs (e.g.captioning), (3) CNNs used in tasks with multi-modal inputs (e.g.visual question answering) or reinforcement learning, all without architectural changes or re-training. We combine Grad-CAM with existing fine-grained visualizations to create a high-resolution class-discriminative visualization, Guided Grad-CAM, and apply it to image classification, image captioning, and visual question answering (VQA) models, including ResNet-based architectures. In the context of image classification models, our visualizations (a) lend insights into failure modes of these models (showing that seemingly unreasonable predictions have reasonable explanations), (b) outperform previous methods on the ILSVRC-15 weakly-supervised localization task, (c) are robust to adversarial perturbations, (d) are more faithful to the underlying model, and (e) help achieve model generalization by identifying dataset bias. For image captioning and VQA, our visualizations show that even non-attention based models learn to localize discriminative regions of input image. We devise a way to identify important neurons through Grad-CAM and combine it with neuron names (Bau et al. in Computer vision and pattern recognition, 2017) to provide textual explanations for model decisions. Finally, we design and conduct human studies to measure if Grad-CAM explanations help users establish appropriate trust in predictions from deep networks and show that Grad-CAM helps untrained users successfully discern a 'stronger' deep network from a 'weaker' one even when both make identical predictions. Our code is available at , along with a demo on CloudCV (Agrawal et al., in: Mobile cloud visual media computing, pp 265-290. Springer, 2015) () and a video at .
6.标题:ClothingOut: a category-supervised GAN model for clothing segmentation and retrieval 作者: Zhang, Haijun; Sun, Yanfang; Liu, Linlin; 等. 期刊:NEURAL COMPUTING & APPLICATIONS 被引频次: 61 摘要:This paper presents a new framework, ClothingOut, which utilizes generative adversarial network (GAN) to generate tiled clothing images automatically. Specifically, we design a novel category-supervised GAN model by learning transformation rules between clothes on wearers and clothes that are tiled. Our method features in adding category attribute to a traditional GAN model. For model training, we built a large-scale dataset containing over 20,000 pairs of wearer images and their corresponding tiled clothing images. The learned model can be straightforwardly applied to video advertising and cross-scenario clothing image retrieval. We evaluated our generated images which can be regarded as the segmentation from the wearer images from two aspects: authenticity and retrieval performance. Experimental results demonstrate the effectiveness of our method.
7.标题:Hierarchical LSTMs with Adaptive Attention for Visual Captioning 作者: Gao, Lianli; Li, Xiangpeng; Song, Jingkuan; 等. 期刊:IEEE TRANSACTIONS ON PATTERN ANALYSIS AND MACHINE INTELLIGENCE 被引频次: 42 摘要:Recent progress has been made in using attention based encoder-decoder framework for image and video captioning. Most existing decoders apply the attention mechanism to every generated word including both visual words (e.g., "gun" and "shooting") and non-visual words (e.g., "the", "a"). However, these non-visual words can be easily predicted using natural language model without considering visual signals or attention. Imposing attention mechanism on non-visual words could mislead and decrease the overall performance of visual captioning. Furthermore, the hierarchy of LSTMs enables more complex representation of visual data, capturing information at different scales. Considering these issues, we propose a hierarchical LSTM with adaptive attention (hLSTMat) approach for image and video captioning. Specifically, the proposed framework utilizes the spatial or temporal attention for selecting specific regions or frames to predict the related words, while the adaptive attention is for deciding whether to depend on the visual information or the language context information. Also, a hierarchical LSTMs is designed to simultaneously consider both low-level visual information and high-level language context information to support the caption generation. We design the hLSTMat model as a general framework, and we first instantiate it for the task of video captioning. Then, we further instantiate our hLSTMarefine it and apply it to the imioning task. To demonstrate the effectiveness of our proposed framework, we test our method on both video and image captioning tasks. Experimental results show that our approach achieves the state-of-the-art performance for most of the evaluation metrics on both tasks. The effect of important components is also well exploited in the ablation study.
8.标题:Alcoholism identification via convolutional neural network based on parametric ReLU, dropout, and batch normalization 作者: Wang, Shui-Hua; Muhammad, Khan; Hong, Jin; 等. 期刊:NEURAL COMPUTING & APPLICATIONS 被引频次: 40 摘要:Alcoholism changes the structure of brain. Several somatic marker hypothesis network-related regions are known to be damaged in chronic alcoholism. Neuroimaging approach can help us better understanding the impairment discovered in alcohol-dependent subjects. In this research, we recruited subjects from participating hospitals. In total, 188 abstinent long-term chronic alcoholic participants (95 men and 93 women) and 191 non-alcoholic control participants (95 men and 96 women) were enrolled in our experiment via computerized diagnostic interview schedule version IV and medical history interview employed to determine whether the applicants can be enrolled or excluded. The Siemens Verio Tim 3.0 T MR scanner (Siemens Medical Solutions, Erlangen, Germany) was employed to scan the subjects. Then, we proposed a 10-layer convolutional neural network for the diagnosis based on imaging, including three advanced techniques: parametric rectified linear unit (PReLU); batch normalization; and dropout. The structure of network is fine-tuned. The results show that our method secured a sensitivity of 97.73 +/- 1.04%, a specificity of 97.69 +/- 0.87%, and an accuracy of 97.71 +/- 0.68%. We observed the PReLU gives better performance than ordinary ReLU, clipped ReLU, and leaky ReLU. The batch normalization and dropout gained enhanced performance as batch normalization overcame the internal covariate shift and dropout got over the overfitting. The results of our proposed 10-layer CNN model show its performance better than seven state-of-the-art approaches.
9.标题:MultiResUNet : Rethinking the U-Net architecture for multimodal biomedical image segmentation 作者: Ibtehaz, Nabil; Rahman, M. Sohel 期刊:NEURAL NETWORKS 被引频次: 39 摘要:In recent years Deep Learning has brought about a breakthrough in Medical Image Segmentation. In this regard, U-Net has been the most popular architecture in the medical imaging community. Despite outstanding overall performance in segmenting multimodal medical images, through extensive experimentations on some challenging datasets, we demonstrate that the classical U-Net architecture seems to be lacking in certain aspects. Therefore, we propose some modifications to improve upon the already state-of-the-art U-Net model. Following these modifications, we develop a novel architecture, MultiResUNet, as the potential successor to the U-Net architecture. We have tested and compared MultiResUNet with the classical U-Net on a vast repertoire of multimodal medical images. Although only slight improvements in the cases of ideal images are noticed, remarkable gains in performance have been attained for the challenging ones. We have evaluated our model on five different datasets, each with their own unique challenges, and have obtained a relative improvement in performance of 10.15%, 5.07%, 2.63%, 1.41%, and 0.62% respectively. We have also discussed and highlighted some qualitatively superior aspects of MultiResUNet over classical U-Net that are not really reflected in the quantitative measures. (C) 2019 Elsevier Ltd. All rights reserved.
10.标题:Feature Boosting Network For 3D Pose Estimation 作者: Liu, Jun; Ding, Henghui; Shahroudy, Amir; 等. 期刊:IEEE TRANSACTIONS ON PATTERN ANALYSIS AND MACHINE INTELLIGENCE 被引频次: 29 摘要:In this paper, a feature boosting network is proposed for estimating 3D hand pose and 3D body pose from a single RGB image. In this method, the features learned by the convolutional layers are boosted with a new long short-term dependence-aware (LSTD) module, which enables the intermediate convolutional feature maps to perceive the graphical long short-term dependency among different hand (or body) parts using the designed Graphical ConvLSTM. Learning a set of features that are reliable and discriminatively representative of the pose of a hand (or body) part is difficult due to the ambiguities, texture and illumination variation, and self-occlusion in the real application of 3D pose estimation. To improve the reliability of the features for representing each body part and enhance the LSTD module, we further introduce a context consistency gate (CCG) in this paper, with which the convolutional feature maps are modulated according to their consistency with the context representations. We evaluate the proposed method on challenging benchmark datasets for 3D hand pose estimation and 3D full body pose estimation. Experimental results show the effectiveness of our method that achieves state-of-the-art performance on both of the tasks.
概念解释 研究热点是指在一段时间内具有大量成果产出和较高研究价值的研究主题。研究热点在文献上的表现为发文量和被引量的快速增长。研究热点不同于研究前沿,研究前沿难以测度和捕获,即使捕获到的前沿,也需要专家进行研判,处于萌芽期的研究热点可以认为是研究前沿。一个研究主题成为研究热点后,通常就不再是研究前沿。尽管如此,研究热点的识别和分析仍具有重要意义,研究热点是经过一段时间和实践检验的研究前沿,对于科学理论的创新和发展具有重要意义,具有较高的应用价值。
数据来源 基于Web of science平台,筛选学科类别为COMPUTER SCIENCE ARTIFICIAL INTELLIGENCE且发表在2018—2020年间的论文,采用InCites数据库中的Citation Topics模块对研究主题进行识别,筛选获得人工智能领域Top20研究热点。
撰稿:June 审核:情报分析与研究部
|